미완성된 포스트입니다.
1 개요
성향점수(PS: Propensity Score)는 처치여부를 공변량으로 설명하여, 각 개인이 처치군에 속할 가능성을 하나의 점수로 요약한 값이다. 여러 공변량을 한꺼번에 비교하기 어렵기 때문에, 처치배정 메커니즘을 하나의 확률값으로 압축하는 아이디어다.
그런데 PS는 기본적으로 처치변수가 이항변수일 때 가장 직관적이다.
\[ T_i \in \{0, 1\} \]
예를 들어:
- 특정 약물을 복용했는가?
- 정부지원사업에 참여했는가?
- 직업훈련을 받았는가?
- 건강검진을 받았는가?
같은 질문은 처치 여부를 0과 1로 나눌 수 있다. 이 경우 성향점수는 다음과 같이 정의된다.
\[ e(X_i) = Pr(T_i = 1 | X_i) \]
개인 \(i\)가 가진 공변량 \(X_i\)를 고려했을 때, 처치군에 속할 조건부 확률이다. 즉, 성향점수 = 처치받을 확률.
하지만 현실의 처치는 꼭 0과 1로 나뉘지 않는다. 약물 복용량은 사람마다 다르고, 정책지원금 규모도 기업마다 다르며, 프로그램 참여기간도 제각각이다. 복용량, 규모, 기간이 연구주제인 경우 PS를 활용하기 어렵다. 이때 필요한 것은 “처치받을 확률”이 아니라 “0.75mg 복용할 확률”이다. 문제는 “0.75mg 복용할 확률”은 0이라는 점. 이 지점에서 일반화 성향점수(GPS: Generalized Propensity Score)가 등장한다.
2 PS가 하는 일
PS가 하는 일은 단순하다. 여러 공변량 \(X\)를 활용하여, 각 관측치가 처치군에 속할 확률을 추정한다. 예를 들어 나이, 성별, 동반질환을 기준으로 특정 약물을 복용할 가능성을 계산하는 것이다.
이렇게 계산된 성향점수는 처치군과 비처치군의 공변량 분포를 비교하거나, 비슷한 사람끼리 묶거나, 가중치를 계산하는 데 사용된다. 즉, PS는 분석대상을 바로 비교하기 전에 처치배정 구조를 요약하는 중간 산출물에 가깝다.
위 더미데이터는 2,000명의 가상 관측치로 구성했다. 공변량은 age, female, comorbidity이다.
이 세 변수가 처치확률 ps_true에 영향을 주고, 이 확률에 따라 처치여부 treat가 결정되도록 설정했다. 다만 실제 분석에서는 ps_true를 알 수 없다. 따라서 관찰된 처치여부 treat와 공변량을 이용해서 성향점수를 다시 추정해야 한다.
위 예시에서 ps는 모델로 추정한 성향점수다. 더미데이터에서는 자료를 생성할 때 사용한 실제 처치확률 ps_true를 알고 있으므로, 추정된 ps가 이를 어느 정도 따라가는지 확인할 수 있다.
cor_ps mean_true mean_est
<num> <num> <num>
1: 0.9979188 0.1877143 0.1805분포를 겹쳐보면 더 직관적이다. 두 밀도곡선이 비슷하게 겹칠수록, 추정된 성향점수 ps가 자료 생성에 사용한 ps_true를 잘 따라간다고 볼 수 있다.
plot_dt <- melt(
dt[, .(id, ps_true, ps)],
id.vars = "id",
variable.name = "type",
value.name = "score"
)
ggplot(
plot_dt,
aes(x = score, fill = type)
) +
geom_density(
alpha = 0.35,
linewidth = 0.9,
aes(color = type)
) +
scale_fill_manual(
values = c(
ps_true = "#E69F00",
ps = "#56B4E9"
),
labels = c(
ps_true = "True PS",
ps = "Estimated PS"
),
name = NULL
) +
scale_color_manual(
values = c(
ps_true = "#E69F00",
ps = "#56B4E9"
),
labels = c(
ps_true = "True PS",
ps = "Estimated PS"
),
name = NULL
) +
labs(
x = "Propensity score",
y = "Density"
) +
theme_classic()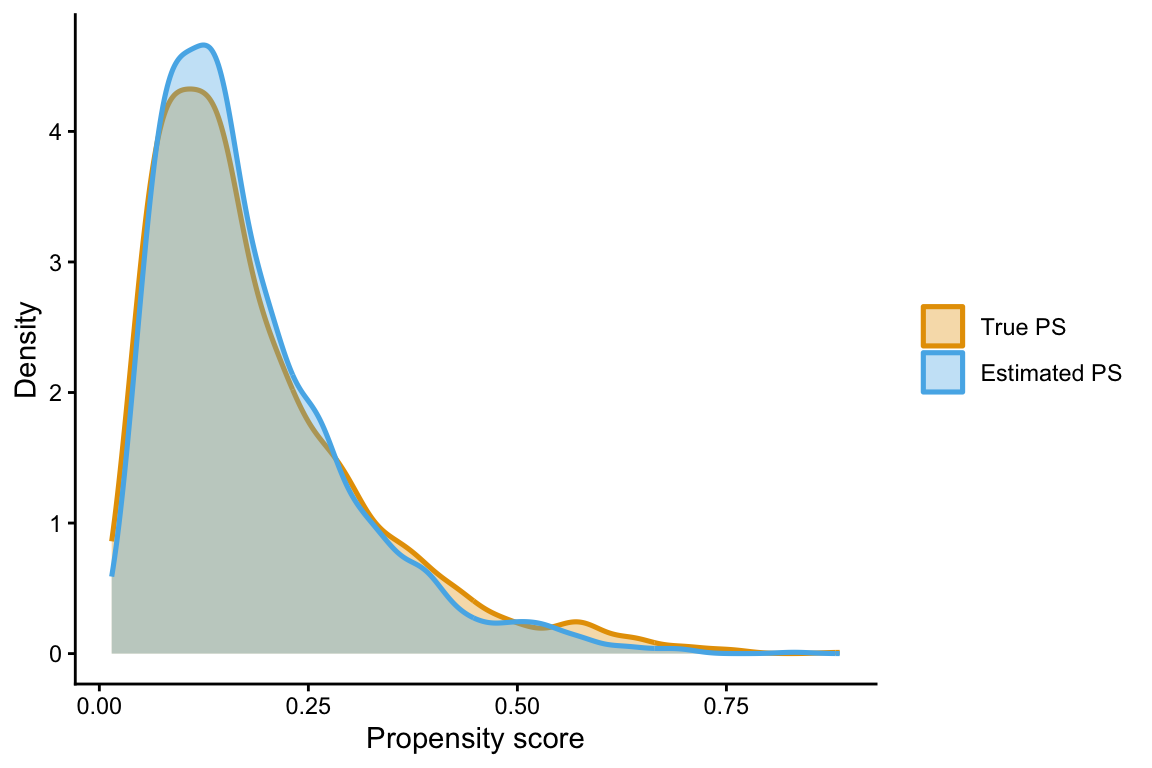
실제 분석에서는 ps_true가 없기 때문에 이런 비교는 불가능하다. 다만 더미데이터에서는 성향점수가 무엇을 추정하는지 확인하기 위해 정답지를 잠시 열어볼 수 있다.
다시 말해 ps는 각 개인이 처치군에 속할 확률이다. 이 점수를 활용하는 방식은 여러 가지다.
- Matching: PS가 비슷한 처치군과 비처치군을 짝짓는다.
- Stratification: PS 분위별로 층화한 뒤 비교한다.
- IPTW: 처치받기 어려웠는데 처치받은 사람, 처치받기 쉬웠는데 처치받지 않은 사람에게 더 큰 가중치를 준다.
- Overlap weighting: 처치군과 비처치군이 실제로 비교 가능한 영역에 더 큰 가중치를 준다.
핵심은 모두 같다. 관찰된 특성을 기준으로 처치배정 구조를 요약하고, 이 요약값을 분석설계에 활용하는 것이다.
3 처치강도는 0과 1이 아니다
현실의 처치는 종종 강도를 갖는다.
- 약물 복용량
- 누적 처방일수
- 치료강도
- 정책지원금 규모
- 직업훈련 참여시간
- 사회서비스 이용횟수
- 보험료율 또는 급여수준
이 경우 질문은 바뀐다.
처치를 받았는가?
가 아니라,
처치를 얼마나 받았는가?
가 된다.
예를 들어 기업지원사업 자료를 분석한다고 하자. 지원받은 기업과 지원받지 않은 기업을 비교할 수도 있다. 하지만 기업마다 지원금 규모가 다르다면, 더 중요한 질문은 다음일 수 있다.
지원금이 1억 원 증가할 때 매출액은 얼마나 달라지는가?
또는 보건의료 연구에서는 다음 질문이 더 자연스럽다.
누적 약물 복용량이 증가할수록 결과변수는 어떻게 달라지는가?
이 경우 처치변수는 이항변수가 아니라 연속형 변수다.
\[ T_i \in \mathbb{R} \]
따라서 단순 PS가 아니라 GPS가 필요하다.
PS는 \(Pr(T_i = 1 | X_i)\)를 추정한다. 이항변수의 경우에는 \(T_i = 1\)이라는 사건의 확률을 직접 계산할 수 있다. 반면 연속형 변수에서는 \(T_i\)가 정확히 어떤 값 \(t\)를 가질 확률은 0이다. 예를 들어 약물 복용량이 정확히 0.75mg일 확률을 묻는 것은 별 의미가 없다.
이 문제는 확률이 아니라 우도로 접근해야 한다. 정확히 0.75mg을 복용할 확률을 묻는 대신, 개인 \(i\)의 공변량 \(X_i\)를 고려했을 때 관찰된 복용량 0.75mg이 얼마나 그럴듯한지 묻는 것이다. 즉, 연속형 처치에서는 특정 값의 확률이 아니라, 관찰된 처치수준의 조건부 밀도 또는 우도의 관점으로 바꿔야 한다.
4 GPS의 기본 아이디어
GPS는 PS를 연속형 처치변수로 확장한 개념이다. PS가 “처치받을 확률”이라면, GPS는 “관찰된 처치수준의 조건부 밀도”에 가깝다.
연속형 처치변수 \(T_i\)가 있고, 공변량 \(X_i\)가 있을 때 GPS는 다음과 같이 정의된다.
\[ r(t, X_i) = f_{T|X}(t | X_i) \]
즉, 개인 \(i\)의 공변량 \(X_i\)가 주어졌을 때, 처치수준 \(t\)를 받을 조건부 밀도다.
이항처치에서 PS가 \(Pr(T_i = 1 | X_i)\)였다면, 연속처치에서는 \(T_i = t\)일 확률밀도함수를 추정한다고 볼 수 있다. 연속형 변수에서 특정한 값 하나를 가질 확률은 0이므로, 확률(probability)이 아니라 밀도(density)를 사용한다. 다르게 말하면, GPS는 각 개인이 실제로 받은 처치수준 \(T_i\)가 공변량 \(X_i\)를 고려했을 때 얼마나 그럴듯하게 관찰될 수 있는지를 나타내는 값이다.
이 점에서 GPS는 우도와 가깝다. 예를 들어 어떤 사람의 나이, 성별, 동반질환을 고려했을 때 예상되는 약물 복용량이 30mg 근처라면, 실제 복용량이 31mg인 경우의 조건부 밀도는 높을 것이다. 반대로 같은 조건에서 실제 복용량이 120mg이라면 조건부 밀도는 낮을 것이다. 즉, GPS는 “이 사람이 이 정도 처치를 받을 법했는가?”를 수량화한다. PS에서 처치배정 확률이 낮은데 처치받은 사람에게 큰 가중치가 붙는 것처럼, GPS에서도 관찰된 처치강도가 조건부분포상 드문 경우라면 분석에서 민감한 관측치가 될 수 있다.
보통은 처치변수의 조건부분포를 가정하고 GPS를 추정한다. 예를 들어 처치강도 \(T\)가 공변량 \(X\)에 따라 정규분포를 따른다고 가정하면 다음과 같이 쓸 수 있다.
\[ T_i | X_i \sim N(\mu_i, \sigma^2) \]
여기서 \(\mu_i\)는 공변량으로 예측한 처치강도다.
dt_gps <- data.table(
id = 1:2000,
age = rnorm(2000, mean = 65, sd = 8),
female = rbinom(2000, 1, 0.55),
comorbidity = rpois(2000, lambda = 2)
)
dt_gps[, dose :=
30 +
0.4 * age -
3 * female +
4 * comorbidity +
rnorm(.N, 0, 8)
]
dt_gps[, dose := pmax(dose, 0)]
gps_model <- lm(dose ~ age + female + comorbidity, data = dt_gps)
dt_gps[, dose_hat := predict(gps_model)]
sigma_hat <- sd(residuals(gps_model))
dt_gps[, gps := dnorm(
dose,
mean = dose_hat,
sd = sigma_hat
)]위 예시에서 gps는 각 개인이 실제로 관찰된 처치강도 dose를 받을 조건부 밀도다. 이 값을 이용하여 처치강도별 반응함수(dose-response function)를 추정할 수 있다.
5 PS와 GPS의 차이
PS와 GPS는 서로 다른 방법이라기보다, 같은 아이디어의 적용범위가 다르다고 보는 편이 낫다.
| 구분 | PS | GPS |
|---|---|---|
| 처치변수 | 이항변수 | 연속형 변수 |
| 핵심값 | 처치받을 조건부 확률 | 특정 처치수준의 조건부 밀도 |
| 대표 질문 | 처치를 받았는가? | 처치를 얼마나 받았는가? |
| 주요 활용 | Matching, weighting, stratification | Dose-response function 추정 |
| 예시 | 약물 복용 여부, 사업 참여 여부 | 약물 복용량, 지원금 규모, 참여기간 |
이 차이는 단순히 기술적인 차이가 아니다. 연구질문 자체가 달라진다. PS는 처치 여부가 다른 두 집단을 구분하는 데 초점이 있고, GPS는 처치강도 \(t\)의 변화에 따라 반응이 어떻게 달라지는지 추적하는 데 초점이 있다. 즉, 하나의 0/1 비교가 아니라 처치강도별 반응곡선을 추정한다.
6 실무적으로 중요한 것
PS든 GPS든 가장 중요한 것은 점수 자체가 아니다. Balance다.
PS를 추정했다면 처치군과 비처치군의 공변량 균형이 실제로 개선되었는지 확인해야 한다. GPS를 추정했다면 처치강도별로 공변량 분포가 충분히 겹치는지 확인해야 한다. 점수를 만들었다는 사실만으로 연구설계가 좋아지지는 않는다.
특히 GPS에서는 처치강도의 양 끝단에서 문제가 자주 발생한다. 예를 들어 매우 높은 용량을 받은 사람은 애초에 중증도가 높았을 가능성이 크다. 매우 낮은 용량을 받은 사람과 비교 가능한 대상이 충분하지 않을 수 있다. 이 경우 dose-response curve의 양 끝단은 매우 불안정하다.
따라서 실무에서는 다음을 반드시 확인해야 한다.
- 처치강도 분포가 충분히 겹치는가?
- 극단적인 처치수준에 관측치가 충분한가?
- GPS 조정 이후 공변량 균형이 개선되었는가?
- 처치강도와 결과변수의 관계가 모델 가정에 과도하게 의존하지 않는가?
7 마치며
PS는 관찰자료에서 처치배정 구조를 요약하기 위한 유용한 도구다. 하지만 현실의 처치는 0과 1로만 존재하지 않는다. 약물은 복용 여부뿐만 아니라 용량과 기간을 갖고, 정책은 참여 여부뿐만 아니라 지원규모와 참여강도를 갖는다.
이처럼 처치가 강도를 가질 때에는 GPS가 자연스러운 확장이다. GPS는 PS보다 더 고급인 방법이라기보다는, 처치변수의 형태가 달라졌을 때 필요한 일반화다.
정리하면 다음과 같다.
PS는 “처치를 받을 확률”을 맞추는 방법이고, GPS는 “그 정도의 처치를 받을 조건부 밀도”를 맞추는 방법이다.
다만 둘 모두 관찰된 공변량에 의존한다. 따라서 PS/GPS를 사용했다는 사실보다 중요한 것은, 어떤 변수로 처치배정 메커니즘을 설명했는지, 그리고 조정 이후 실제로 비교 가능한 상태가 되었는지다.