1 개요
성향점수(propensity score)는 Rosenbaum과 Rubin이 1983년 관찰자료의 인과효과 추정에서 여러 공변량을 단일 점수로 요약해 “차원의 저주 문제”를 일부 해소하고, 여러 변수의 불균형 문제를 단일 변수의 불균형 문제로 치환(축약)하기 위해 제안한 방법이다.1 거창해보이지만 현대적 분석방법론 관점에서 성향점수는 곧 처치를 받을 확률을 의미한다.
보다 엄밀히 말하자면, 성향점수는 공변량 \(X_i\)가 주어졌을 때 개인 \(i\)가 처치를 받을 조건부 확률이다.
\[ PS_i = Pr(T_i = 1 \mid X_i) \]
PS matching 처치군과 비처치군 중 이 확률이 비슷한 행끼리 짝을 지어서, 관찰된 공변량 분포를 최대한 비슷하게 만드는 것이 핵심 골자다. 바꿔말하면 인위적인 방법으로 처치군과 비처치군의 평균적 특징을 비슷하게 맞춰주려는 시도인 셈. 생각보다 성능도 괜찮다.1
그런데 문제는, 처치변수가 연속변수일 때다.2 대표적으로 dose-response 모델과 같이 처치의 총량이 주요한 연구주제인 경우, 위와 같은 방식으로는 적용이 어렵다.
2 연속변수와 확률
이산형 사건에서는 특정한 값 하나를 가질 확률을 계산할 수 있다.
주사위를 던져서 3이 나올 확률?
그러나 연속형 사건에서 특정한 값 하나를 정확히 가질 확률은 0이다. 1에서 6사이의 숫자 중 하나를 뽑았을 때, 그 숫자가 3일 확률은 0이다. 총 사건의 갯수가 무한으로 셀 수 없기 때문이다.
\[ Pr(T_i = t | X_i) = 0 \]
연속형 사건에서는 특정한 값 하나가 나타날 확률이 아니라, 특정한 범위 안에 값이 포함될 확률을 계산한다.
1에서 6 사이의 실수 중 하나를 무작위로 뽑았을 때 그 숫자가 2보다 크고 4보다 작을 확률은?
\[ Pr(2 < T < 4) > 0 \]
3 PS가 하는 일
PS는 쉽게 산출된다. 처치여부를 선형예측한뒤(LPM), 그 결과를 로지스틱 함수에 연결하여 0에서 1 사이의 값으로 만들면 끝. 먼저 더미데이터를 만들어서 그 성능을 확인해보자. PS는 처치배정구조를 얼마나 잘 요약해줄까?
더미데이터는 2,000명의 가상 관측치로 구성했다. 공변량은 age, female, comorbidity.
RCT라면 처치가 무작위로 배정되어야 하지만, 실제 세상은 그렇지 않은 경우가 많다. 나이가 많고, 여성이고, 동반질환이 높을수록 병원에 갈 일이 많아서 처치받을 확률이 증가한다고 가정해보자. plogis() 함수로 처치받을 확률을 인위적으로 만든 뒤, 이 확률에 따라 처치여부를 배정해주자.3 당연하지만 실제로는 이 ps_true는 알 수 없다.
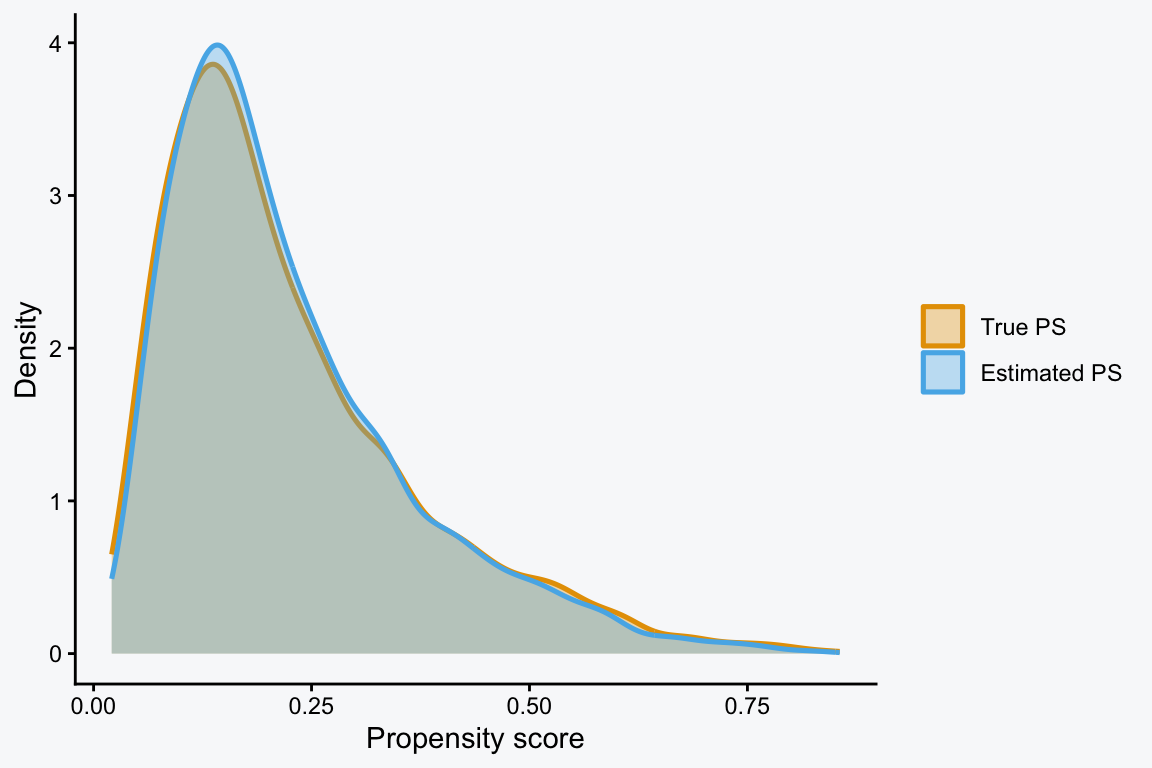
이제 로지스틱 회귀분석으로 PS(ps) 값을 추정하자. 추정된 ps가 ps_true를 어느 정도 따라가는지 확인할 수 있다. 표를 보면, ps는 ps_true를 얼추 비슷하게 따르는 것으로 보인다.
ps_model <- glm(
treat ~ age + female + comorbidity,
data = dt,
family = binomial()
)
dt[, ps := predict(ps_model, type = "response")]
head(dt) %>% kable(digits = 2)| id | age | female | comorbidity | ps_true | treat | ps |
|---|---|---|---|---|---|---|
| 1 | 68.49 | 0 | 1 | 0.15 | 0 | 0.16 |
| 2 | 49.36 | 1 | 2 | 0.08 | 0 | 0.09 |
| 3 | 60.15 | 0 | 1 | 0.09 | 0 | 0.10 |
| 4 | 59.80 | 1 | 2 | 0.16 | 0 | 0.16 |
| 5 | 70.08 | 0 | 1 | 0.16 | 0 | 0.17 |
| 6 | 68.92 | 1 | 0 | 0.13 | 0 | 0.13 |
분포를 겹쳐보면 더 직관적이다. 두 밀도곡선이 비슷하게 겹칠수록, 추정된 성향점수 ps가 자료 생성에 사용한 ps_true를 잘 따라간다고 볼 수 있다.4
Code
plot_dt <- melt(
dt[, .(id, ps_true, ps)],
id.vars = "id",
variable.name = "type",
value.name = "score"
)
ggplot(plot_dt, aes(x = score, fill = type)) +
geom_density(
alpha = 0.35,
linewidth = 0.9,
aes(color = type)
) +
scale_fill_manual(
values = c(ps_true = "#E69F00", ps = "#56B4E9"),
labels = c(ps_true = "True PS", ps = "Estimated PS"),
name = NULL
) +
scale_color_manual(
values = c(ps_true = "#E69F00", ps = "#56B4E9"),
labels = c(ps_true = "True PS", ps = "Estimated PS"),
name = NULL
) +
labs(x = "Propensity score", y = "Density") +
theme_classic() +
theme(
plot.background = element_rect(fill = "#f8f9fa", color = NA),
panel.background = element_rect(fill = "#f8f9fa", color = NA),
legend.background = element_rect(fill = "#f8f9fa", color = NA),
legend.key = element_rect(fill = "#f8f9fa", color = NA)
)
Code
ggplot(plot_dt, aes(x = score, fill = type)) +
geom_density(
alpha = 0.35,
linewidth = 0.9,
aes(color = type)
) +
scale_fill_manual(
values = c(ps_true = "#F2B84B", ps = "#7CC7F2"),
labels = c(ps_true = "True PS", ps = "Estimated PS"),
name = NULL
) +
scale_color_manual(
values = c(ps_true = "#F2B84B", ps = "#7CC7F2"),
labels = c(ps_true = "True PS", ps = "Estimated PS"),
name = NULL
) +
labs(x = "Propensity score", y = "Density") +
theme_classic() +
theme(
plot.background = element_rect(fill = "#212529", color = NA),
panel.background = element_rect(fill = "#212529", color = NA),
legend.background = element_rect(fill = "#212529", color = NA),
legend.key = element_rect(fill = "#212529", color = NA),
text = element_text(color = "#f8f9fa"),
axis.text = element_text(color = "#f8f9fa"),
axis.line = element_line(color = "#f8f9fa"),
axis.ticks = element_line(color = "#f8f9fa")
)
4 GPS의 기본 아이디어
처치가 복용량처럼 연속형이면 특정 복용량을 정확히 처치받을 확률은 0이므로, 이항처치에서 사용하던 확률을 그대로 적용할 수 없다.
대신 관찰된 처치수준이 그 사람의 특성에 비추어 얼마나 자연스러운지를 평가한다. 예를 들어 나이, 성별, 동반질환으로 보아 30mg 근처를 처방받을 법한 사람이 실제로 31mg을 받았다면 그 처치수준은 자연스럽다고 볼 수 있다(분산이 충분히 작다고 가정한다). 반면 120mg을 받았다면 관찰되기 어렵고 부자연스럽다.
일반화 성향점수(GPS: Generalized Propensity Score)는 바로 이 차이를 수량화한다. 연속형 처치변수 \(T_i\)와 공변량 \(X_i\)가 있을 때, GPS는 개인 \(i\)가 실제로 받은 처치수준에서 평가한 조건부 밀도다.
\[ GPS_i = f_{T \mid X}(T_i \mid X_i) \]
따라서 PS가 “이 사람이 처치를 받을 법했는가?”를 나타낸다면, GPS는 “이 사람이 실제로 받은 만큼의 처치를 받을 법했는가?”를 나타낸다. 둘 다 관찰된 공변량으로 처치배정 구조를 요약하지만, PS는 조건부 확률을, GPS는 조건부 확률밀도를 사용한다.
이항처치에서 PS는 처치군과 비처치군 사이에 다르게 분포하는 공변량을 하나의 점수로 요약하는 balancing score다. 연속처치에서 GPS도 같은 역할을 한다. Hirano와 Imbens는 각 처치수준 \(t\)에서 GPS가 같은 관측치끼리 비교하면, 관찰된 공변량 차이 때문에 해당 수준의 처치를 받을 가능성이 달라지는 문제를 조정할 수 있음을 보였다.2
물론 GPS가 관찰되지 않은 교란까지 없애주는 것은 아니다. 어디까지나 PS를 확장한 방법론임을 기억하자.5
4.1 1단계: 처치 모형 추정
장황하지만, 어쨌든 PS랑 기본 아이디어는 같다. 실제복용량을 좌변에 두고 공변량으로 선형추정하여 얻어진 값으로 복용량의 분포를 설정한다. 그리고 이 분포를 활용하여 실제복용량이 얼마나 자연스러운 값인지를 평가한다. 예를 들어 처치강도 \(T_i\)가 공변량 \(X_i\)에 따라 정규분포를 따른다고 가정하면 다음과 같이 쓸 수 있다.
\[ T_i \mid X_i \sim N(\mu_i, \sigma^2) \]
여기서 \(\mu_i\)는 공변량으로 예측한 복용량, 즉 처치강도다. 표준편차는 예측한 복용량의 표준편차가 아니라 실제 복용량과 예측한 복용량의 차이, 즉 잔차의 표준편차임에 주의하자. 조건부 확률밀도이기 때문. 앞에서 PS를 추정한 동일한 2,000명에게 이번에는 연속형 처치량 dose를 추가해보자. 공변량을 선형예측한 처치량은 dose_hat.
dt %>%
.[, dose :=
30 + 0.4 * age - 3 * female + 4 * comorbidity + rnorm(.N, 0, 8)] %>%
.[, dose := pmax(dose, 0)]
gps_model <- lm(dose ~ age + female + comorbidity, data = dt)
dt[, dose_hat := predict(gps_model)]
sigma_hat <- sd(residuals(gps_model))
head(dt) %>% kable(digits = 2)| id | age | female | comorbidity | ps_true | treat | ps | dose | dose_hat |
|---|---|---|---|---|---|---|---|---|
| 1 | 68.49 | 0 | 1 | 0.15 | 0 | 0.16 | 54.10 | 60.81 |
| 2 | 49.36 | 1 | 2 | 0.08 | 0 | 0.09 | 50.93 | 54.31 |
| 3 | 60.15 | 0 | 1 | 0.09 | 0 | 0.10 | 59.07 | 57.21 |
| 4 | 59.80 | 1 | 2 | 0.16 | 0 | 0.16 | 59.48 | 58.82 |
| 5 | 70.08 | 0 | 1 | 0.16 | 0 | 0.17 | 58.86 | 61.50 |
| 6 | 68.92 | 1 | 0 | 0.13 | 0 | 0.13 | 57.81 | 54.62 |
4.2 2단계: GPS 산출
GPS는 실제로 관찰된 처치량 \(T_i\)를 위에서 추정한 조건부분포에 대입해 산출한 확률밀도다. 정규분포를 가정했으므로 다음과 같이 계산한다.
\[ \widehat{GPS}_i = \frac{1}{\sqrt{2\pi\widehat{\sigma}^2}} \exp\left[ -\frac{(T_i - \widehat{\mu}_i)^2}{2\widehat{\sigma}^2} \right] \]
개인별 조건부분포의 중심은 dose_hat이고, 퍼짐은 잔차의 표준편차 sigma_hat이다. 즉, dose_hat의 표준편차가 아니라 sigma_hat을 사용하여 실제 dose의 확률밀도를 평가한다. R에서는 dnorm()이 이 계산을 수행한다.
이제 예시적으로 위에서 만든 dt에서 실제 복용량 dose가 예측 복용량 dose_hat과 가까운 관측치와, 멀리 떨어진 관측치를 하나씩 찾자. 두 관측치는 관찰된 복용량이 조건부 복용량 분포의 평균에 얼마나 가까운지에 따라 GPS가 크게 달라진다.
| ID | 사례 | 추정한 복용량 | 잔차표준편차 | GPS |
|---|---|---|---|---|
| 108 | 추정값과 유사한 사례 | 52.664 | 8.112 | 0.048 |
| 361 | 추정값에서 먼 사례 | 63.264 | 8.112 | 0.000 |
아래 그림은 이 두 관측치의 조건부분포를 각각 그린 것이다. 파란 점선은 공변량으로 예측한 복용량 dose_hat, 주황색 점은 실제 관찰된 복용량 dose에서의 조건부 밀도, 즉 GPS다.
Code
density_dt <- example_dt[
,
{
x <- seq(dose_hat - 4 * sigma_hat, dose_hat + 4 * sigma_hat, length.out = 300)
.(x = x, density = dnorm(x, mean = dose_hat, sd = sigma_hat))
},
by = .(id, case_order, case, facet_case, dose, dose_hat)
]
density_dt[, facet_case := factor(facet_case, levels = example_id[order(case_order), facet_case])]
example_dt[, facet_case := factor(facet_case, levels = example_id[order(case_order), facet_case])]
plot_gps_density <- function(density_fill, dose_color, dark = FALSE) {
p <- ggplot(density_dt, aes(x = x, y = density)) +
geom_area(fill = density_fill, alpha = 0.30) +
geom_line(color = density_fill, linewidth = 0.9) +
geom_segment(
data = example_dt,
aes(
x = dose,
xend = dose,
y = 0,
yend = dnorm(dose, mean = dose_hat, sd = sigma_hat)
),
color = dose_color,
linewidth = 0.9,
inherit.aes = FALSE
) +
geom_point(
data = example_dt,
aes(
x = dose,
y = dnorm(dose, mean = dose_hat, sd = sigma_hat)
),
color = dose_color,
size = 2.5,
inherit.aes = FALSE
) +
geom_vline(
data = example_dt,
aes(xintercept = dose_hat),
color = density_fill,
linetype = "dashed",
linewidth = 0.6
) +
facet_wrap(~ facet_case, scales = "free_x") +
labs(
x = "Dose",
y = "Conditional density",
caption = "Dashed line: predicted dose; orange point: observed dose and its GPS"
) +
theme_classic()
if (dark) {
return(
p +
theme(
plot.background = element_rect(fill = "#212529", color = NA),
panel.background = element_rect(fill = "#212529", color = NA),
strip.background = element_rect(fill = "#343a40", color = NA),
strip.text = element_text(color = "#f8f9fa"),
text = element_text(color = "#f8f9fa"),
axis.text = element_text(color = "#f8f9fa"),
axis.line = element_line(color = "#f8f9fa"),
axis.ticks = element_line(color = "#f8f9fa")
)
)
}
p +
theme(
plot.background = element_rect(fill = "#f8f9fa", color = NA),
panel.background = element_rect(fill = "#f8f9fa", color = NA),
strip.background = element_rect(fill = "#e9ecef", color = NA)
)
}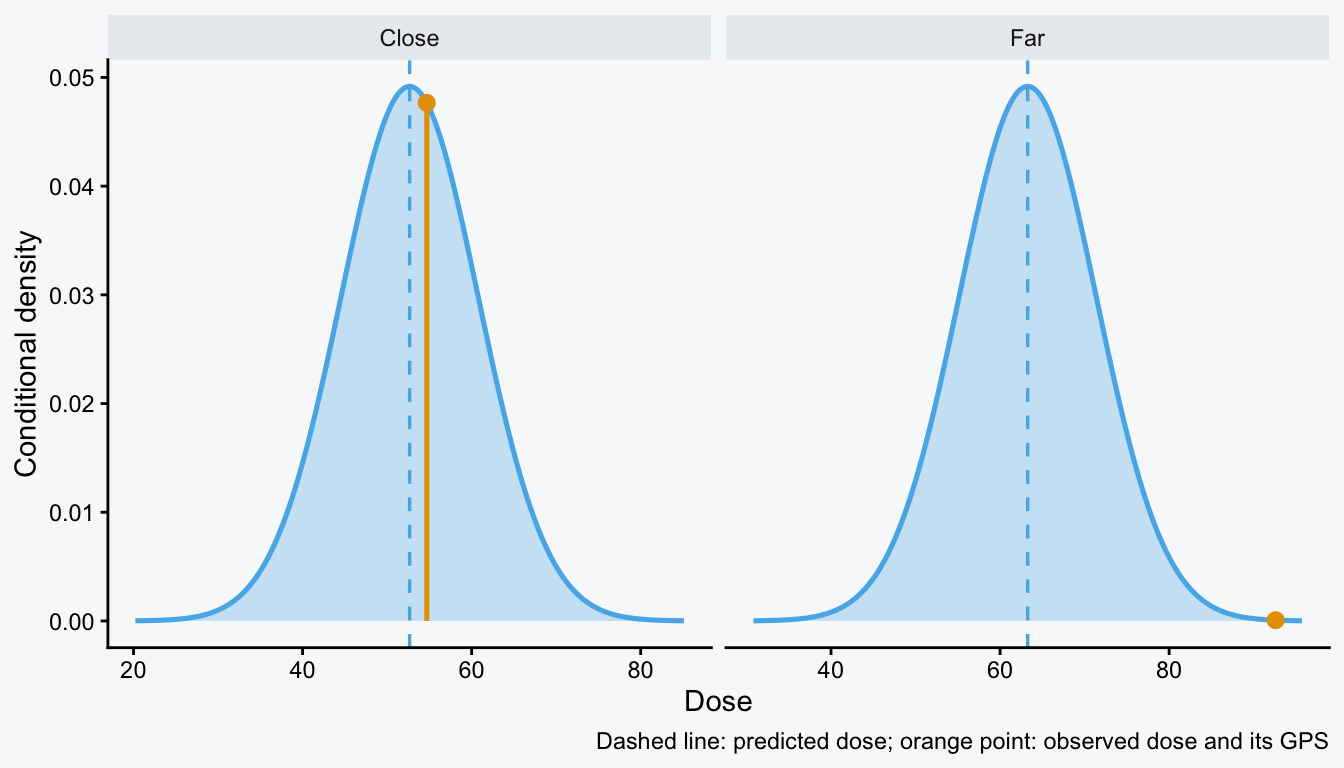
위 예시에서 gps는 각 개인이 실제로 관찰된 처치강도 dose를 받을 조건부 밀도다. gps가 낮은 관측치는 현재 공변량을 가진 사람에게는 드문 복용량을 받은 경우다.
4.3 3단계: Dose-response function 추정
GPS를 계산하는 것만으로 인과효과가 추정되지는 않는다. 마지막 단계에서는 결과변수 \(Y_i\)를 실제 처치량 \(T_i\)와 산출된 GPS로 설명하는 결과 모형을 적합한다.
자세한 내용은 다음 글에서 다룬다.
5 실무적으로 중요한 것
PS든 GPS든 가장 중요한 것은 점수 자체가 아니다.
PS를 추정했다면 처치군과 비처치군의 공변량 균형이 실제로 개선되었는지 확인해야 한다. GPS를 추정했다면 처치강도별로 공변량 분포가 충분히 겹치는지 확인해야 한다.
그리고, 특히 GPS에서는 처치강도의 양 끝단에서 문제가 자주 발생한다. 예를 들어 매우 높은 용량을 받은 사람은 애초에 중증도가 높았을 가능성이 크다. 매우 낮은 용량을 받은 사람과 비교 가능한 대상이 충분하지 않을 수 있다. 이 경우 dose-response curve의 양 끝단은 매우 불안정하다.
따라서 실무에서는 다음을 반드시 확인해야 한다.
- 처치강도 분포가 충분히 겹치는가?
- 극단적인 처치수준에 관측치가 충분한가?
- GPS 조정 이후 공변량 균형이 개선되었는가?
- 처치강도와 결과변수의 관계가 모델 가정에 과도하게 의존하지 않는가?
References
Footnotes
다른 포스트에서 설명하겠지만, 물론 한계도 있다.↩︎
약물 투여량, 지원받은 횟수, 흡연량 등↩︎
이렇게 인위적으로 만든 처치확률과 PS로 추정한 처치확률이 얼마나 일치하는지를 확인하여, PS의 성능을 간접적으로 확인해볼 수 있다.↩︎
다시 말해
ps는 각 개인이 처치군에 속할 확률이다. 이 점수는 PS가 비슷한 처치군과 비처치군을 짝짓는 matching, PS 분위별로 층화한 뒤 비교하는 stratification, 처치받기 어려웠는데 처치받은 사람이나 처치받기 쉬웠는데 처치받지 않은 사람에게 더 큰 가중치를 주는 IPTW, 두 집단이 실제로 비교 가능한 영역에 더 큰 가중치를 주는 overlap weighting 등에 활용된다. 모두 관찰된 특성을 기준으로 처치배정 구조를 요약하고, 그 요약값을 분석설계에 활용한다는 점에서는 같다.↩︎이 방법은 모든 처치수준 \(t\)에 대해 관찰된 공변량 \(X_i\)를 조건으로 하면 처치배정과 잠재결과 \(Y_i(t)\)가 독립이라는 가정을 전제로 한다: \(Y_i(t) \perp T_i \mid X_i \quad \text{for every } t\). 이 가정이 성립한다면 고차원의 공변량 \(X_i\)를 매번 직접 조정하는 대신, 처치수준별 GPS를 이용하여 평균 반응을 추정할 수 있다.↩︎