초안입니다. SCCS의 조건부 우도 전개, 반복사건 확장, event-dependent exposure 문제는 추가 정리가 필요합니다.
개요
지난 포스트에서는 FE(fixed effects)와 SCCS(self-controlled case series)가 각 개인을 자기 자신의 대조군으로 사용한다는 아이디어를 공유한다고 정리했다.
이번 포스트에서는 그 아이디어가 실제 추정식과 데이터 구조에서 어떻게 구현되는지 정리한다. 핵심은 세 가지다.
- 분석 단위는 사람이 아니라 개인-시간구간(person-time interval)이다.
- 개인별로 고정된 위험도 \(\alpha_i\)는 조건부 포아송 우도에서 제거된다.
- 남는 비교는 같은 사람 내부에서의 노출 위험구간과 비노출 구간의 사건 발생률 차이다.
SCCS의 기본 모형
개인 \(i\)의 시간구간 \(t\)에서 사건 발생률을 \(\lambda_{it}\)라고 하자. 노출 여부는 \(x_{it}\), 연령대나 calendar time처럼 시간에 따라 바뀌는 보정변수는 \(z_{it}\)로 둔다.
\[
\lambda_{it}
= \exp(\alpha_i + \beta x_{it} + \gamma z_{it})
\]
여기서 \(\alpha_i\)는 개인의 고정된 위험도다. 성별, 유전적 요인, 장기적인 건강상태처럼 관찰되지 않았더라도 시간에 따라 변하지 않는 요인이 이 안에 들어간다.
포아송 평균은 관찰시간 \(\Delta_{it}\)를 반영해 다음처럼 쓸 수 있다.
\[
\mu_{it}
= \Delta_{it}\exp(\alpha_i + \beta x_{it} + \gamma z_{it})
\]
SCCS는 개인별 전체 사건 수에 조건부로 우도를 만든다. 단순화를 위해 개인 \(i\)에게 사건이 한 번 발생했다고 하면, 그 사건이 특정 구간 \(t\)에 발생할 조건부 확률은 다음과 같다.
\[
\Pr(T_i=t \mid \sum_s y_{is}=1)
=
\frac{\Delta_{it}\exp(\alpha_i + \beta x_{it} + \gamma z_{it})}
{\sum_s \Delta_{is}\exp(\alpha_i + \beta x_{is} + \gamma z_{is})}
\]
분자와 분모에 모두 \(\exp(\alpha_i)\)가 들어가므로 약분된다.
\[
\Pr(T_i=t \mid \sum_s y_{is}=1)
=
\frac{\Delta_{it}\exp(\beta x_{it} + \gamma z_{it})}
{\sum_s \Delta_{is}\exp(\beta x_{is} + \gamma z_{is})}
\]
이게 SCCS의 핵심이다. 개인 간 비교가 아니라 개인 내부의 시간구간 비교만 남기 때문에, 시간에 따라 변하지 않는 교란요인은 추정식에서 사라진다.
데이터 구조
SCCS 자료는 wide 형태보다 long 형태가 자연스럽다. 한 사람의 관찰기간을 노출 시작, 노출 종료, 사건 발생 시점, 연령대 변화 시점 등에 따라 잘라서 여러 행으로 만든다.
library(data.table)
library(ggplot2)
set.seed(20260603)
# 개인 단위 가상자료
# - 모든 사람은 관찰기간 중 사건을 1회 경험한 case로 가정
# - 노출기간은 28일
# - 예시를 명확히 보이기 위해 노출기간의 사건 발생확률을 약간 높게 설정
n_id <- 300
person <- data.table(
id = 1:n_id,
obs_start = 0,
obs_end = 365
)
person[, exposure_start := sample(30:300, .N, replace = TRUE)]
person[, exposure_end := pmin(exposure_start + 28, obs_end)]
person[
,
event_day := {
days <- 1:365
event_weight <- ifelse(
days >= exposure_start & days <= exposure_end,
2.2,
1
)
sample(days, 1, prob = event_weight)
},
by = id
]
# 개인별 관찰기간을 노출 시작/종료 시점으로 분할
DT <- person[
,
{
cut_points <- sort(unique(c(
obs_start,
exposure_start,
exposure_end,
obs_end
)))
data.table(
tstart = head(cut_points, -1),
tend = tail(cut_points, -1)
)
},
by = .(id, obs_start, obs_end, exposure_start, exposure_end, event_day)
]
DT[, person_time := tend - tstart]
DT <- DT[person_time > 0]
# 해당 구간이 노출 위험구간인지 표시
DT[, exposed := as.integer(tstart < exposure_end & tend > exposure_start)]
# 사건일이 해당 구간에 포함되는지 표시
DT[, event := as.integer(event_day > tstart & event_day <= tend)]
# 시간에 따라 변하는 보정변수 예시
# 실제 연구에서는 연령대, calendar month, season 등을 넣는다.
DT[
,
age_band := cut(
tstart,
breaks = c(0, 90, 180, 270, 365),
include.lowest = TRUE,
labels = c("0-90", "91-180", "181-270", "271-365")
)
]
DT[, .(id, tstart, tend, person_time, exposed, event, age_band)][1:10]
id tstart tend person_time exposed event age_band
<int> <num> <num> <num> <int> <int> <fctr>
1: 1 0 284 284 0 1 0-90
2: 1 284 312 28 1 0 271-365
3: 1 312 365 53 0 0 271-365
4: 2 0 232 232 0 1 0-90
5: 2 232 260 28 1 0 181-270
6: 2 260 365 105 0 0 181-270
7: 3 0 155 155 0 1 0-90
8: 3 155 183 28 1 0 91-180
9: 3 183 365 182 0 0 181-270
10: 4 0 152 152 0 1 0-90
발생률 확인
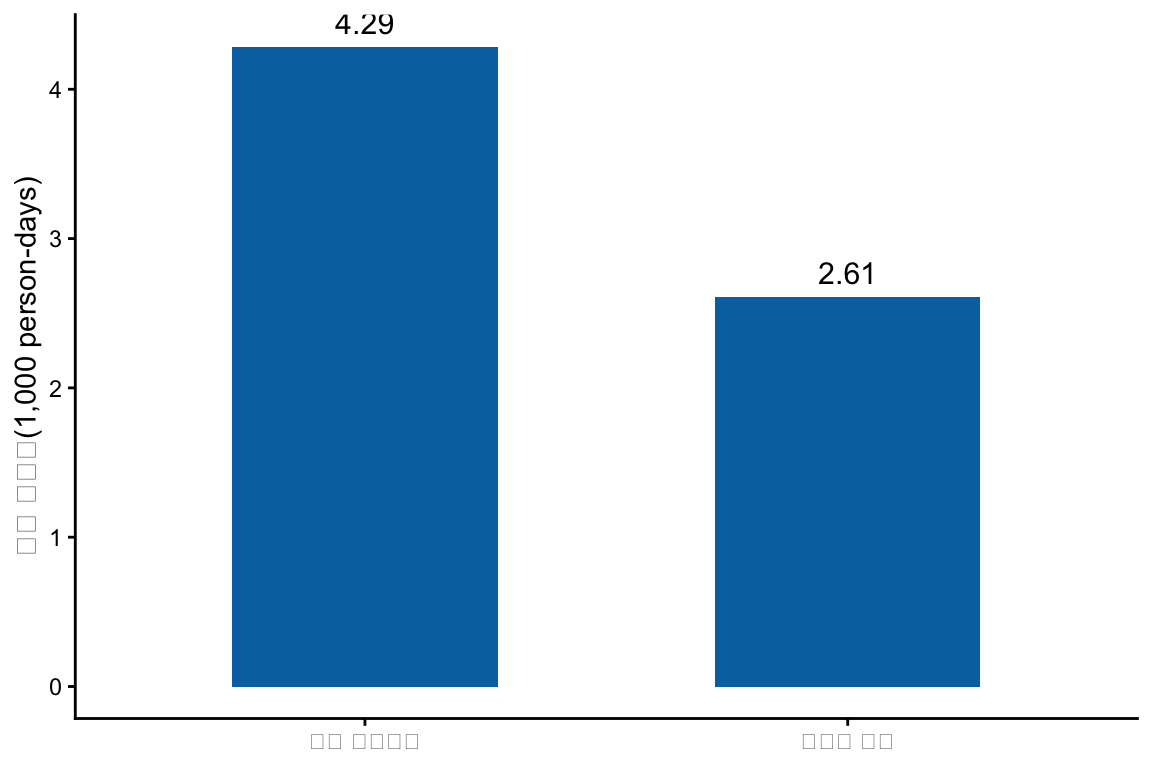
모형을 넣기 전에 노출구간과 비노출구간의 조발생률을 먼저 확인한다. 이 값은 아직 개인 고정효과와 시간 효과를 정식으로 통제한 추정치는 아니지만, 자료 구조가 의도대로 만들어졌는지 확인하는 데 유용하다.
rate_dt <- DT[
,
.(
events = sum(event),
person_time = sum(person_time)
),
by = exposed
]
rate_dt[, rate_1000_days := events / person_time * 1000]
rate_dt[, exposure_group := ifelse(exposed == 1, "노출 위험구간", "비노출 구간")]
ggplot(rate_dt, aes(x = exposure_group, y = rate_1000_days)) +
geom_col(fill = "#0072B2", width = 0.55) +
geom_text(
aes(label = round(rate_1000_days, 2)),
vjust = -0.6,
size = 4
) +
labs(x = NULL, y = "사건 발생률(1,000 person-days)") +
theme_classic()
고정효과 포아송 회귀로 구현하기
작은 예시 자료에서는 개인 고정효과를 factor(id)로 직접 넣어도 된다. 실제 대규모 자료에서는 조건부 포아송 회귀 또는 고정효과 포아송 회귀 전용 구현을 쓰는 편이 낫다.
sccs_fit <- glm(
event ~ exposed + age_band + factor(id) + offset(log(person_time)),
family = poisson(),
data = DT
)
beta <- coef(sccs_fit)["exposed"]
se <- sqrt(diag(vcov(sccs_fit)))["exposed"]
result <- data.table(
term = "노출 위험구간",
irr = exp(beta),
lcl = exp(beta - 1.96 * se),
ucl = exp(beta + 1.96 * se)
)
result
term irr lcl ucl
<char> <num> <num> <num>
1: 노출 위험구간 1.744522 1.211748 2.511541
여기서 exp(beta)는 incidence rate ratio(IRR)다. IRR이 1보다 크면, 같은 개인 안에서 비노출 구간보다 노출 위험구간의 사건 발생률이 높다는 뜻이다.
중요한 점은 이 추정치가 “노출군 vs 비노출군” 비교가 아니라는 것이다. SCCS의 비교는 같은 사람 내부에서 이루어진다. 따라서 개인 간에 고정된 차이, 예를 들어 유전적 취약성이나 장기적인 건강상태 차이는 모형에서 제거된다.
SCCS가 깨지는 지점
SCCS가 항상 좋은 것은 아니다. 자기 자신을 대조군으로 쓰는 장점은 강하지만, 그만큼 설계 가정이 분명하다.
- 사건이 노출 이후의 추적 가능성이나 관찰기간을 바꾸면 문제가 생긴다.
- 사건 발생이 이후 노출 가능성을 바꾸면 event-dependent exposure 문제가 생긴다.
- 연령, 계절, calendar time처럼 시간에 따라 변하는 위험요인은 별도로 보정해야 한다.
- 사건이 너무 잦거나 사건 간 독립성이 약하면 반복사건 모형을 더 신중히 다뤄야 한다.
- 노출 위험구간의 길이와 washout 기간은 임상적 근거로 정해야 한다.
즉, SCCS는 비관측 시불변 교란을 강하게 제거하지만, 시간에 따라 변하는 교란과 사건-노출 순서 문제까지 자동으로 해결하지는 않는다.
마치며
SCCS는 FE 모델의 역학 버전이라고 말할 수 있다. 하지만 단순히 개인 더미를 넣는 회귀분석으로만 이해하면 부족하다. 핵심은 먼저 관찰기간을 올바르게 자르고, 노출 위험구간을 정의하고, 사건이 그 구간 중 어디에서 발생했는지 비교하는 설계에 있다.
다음에 보완할 내용은 두 가지다.
- 실제 건강보험 청구자료에서 처방일, 투약기간, 사건일을 이용해 SCCS long data를 만드는 절차
- SCCS에서 event-dependent exposure와 event-dependent observation period를 점검하는 방법